Hey, sorcererxw here.
I'm a software engineer that focuses on turning ideas into fantastic products. I share something I known through articles and the Telegram channel.


搞笑的是,老板只会问“都有ai了,为什么单测覆盖率不能100%”,根本不会问这个单测是不是有用,能不能维护。 下一回换个人/agent来开发,一股脑删掉重新生成一遍单测。
我发现AI写的那些测试用例,一点都不靠谱,很多bug都看不出来,感觉就是面子工程。

只是从 idea 不值钱,变成了 idea 和 code 都不值钱,ship 变成真正值钱的一部分。
以前我们说 idea 不值钱,现在有了 cc 和 codex 发现 idea 可以很值钱。
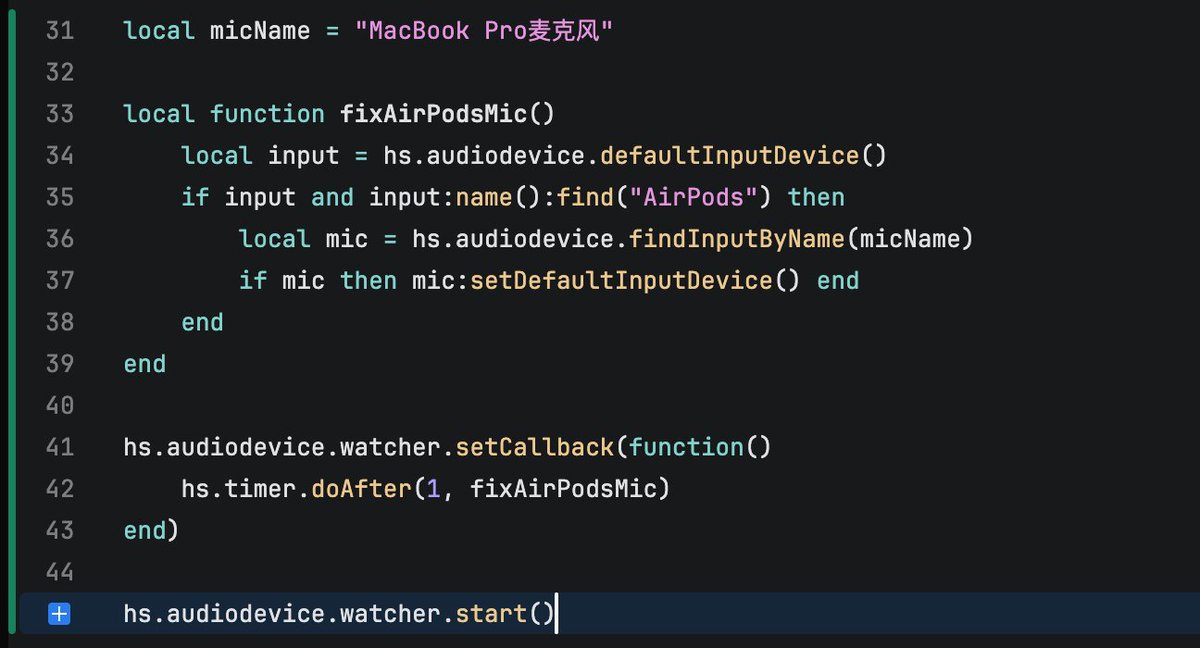
本来想着在 skill 嵌入 script 就能替代 CLI。 现在发现因为 sandbox 机制,纯 skill 搞不定持久化鉴权。 打算还是得把 CLI 跟 skill 给拆开。
有点陷入困境了。 原来在 agent 的沙盒环境中,skill 无法可靠地在本地持久化鉴权状态。 这意味着,如果 skill 的行为依赖带鉴权地访问服务端,那最终交付的就必须是 MCP,而不能只是一个 skill。



看到 brew 终于有 Trae 的 cask 了,安装一个试试看。之前体验过AI生成生成前端的工具,但是从来没有尝试过生成一个正儿八经的小工具。今天试试看用 Trae builder 模式“复刻”了下我的一年前的写的小工具,可以用来计算免息分期的实际价值。 老版本 https://0apr.sorcererxw.com/ 新版本 https://0apr-ai.sorcererxw.com/ 整个开发过程全是 AI (Claude-3.5-sonnet),没有改过一行代码,看着效果还不错,甚至胜过我之前的版本 同时也供君品鉴AI写的代码:https://github.com/sorcererxw/0apr-ai


最近在写一个 TUI 的程序,深度使用了一下风很大的 bubbletea,锐评一下: 1. 易于构建大型复杂界面 将界面上每一个元素抽象为 model,拆分逻辑执行函数 Update 和视图渲染函数 View,在组件 Update 当中可以消费全局各种消息更新自身状态,View 当中专注渲染画面,很像 MVVM 架构。通过这种方式可以很容易创造出事件驱动的 UI 架构,对于构建复杂的交互程序很有帮助。 2. 存在界面刷新闪烁问题 可能因为封装比较浅,每一个组件渲染是输出字符串,框架视角下每次渲染是获取整个页面的字符串,很难做到根据变更区域按需要渲染,每次发生元素变更可能导致整行或者整页刷新,页面会闪烁一下,体验比较差。 对比我常用的 TUI 工具,在相同的terminal+shell下,zellij、lazygit、bottom 等,它们并有类似的情况。
https://planetscale.com/docs/concepts/hobby-plan-deprecation-faq PlanetScale 居然开始全面收费了,原来的免费实例会自动休眠。我有几个定时任务还在依赖 PlanetScale 的 MySQL,刚发现已经好些天没有成功运行了。研究了半天,我才发现是 Planetscale 的 DB 挂了,太无语了。 https://planetscale.com/blog/planetscale-forever 估计对于 PS 来说,云数据库 SaaS 业务增长基本到头了,再深入得横向扩展很多业务。倒不如砍掉营销和销售,保持一个收支平衡的状态,专注服务好当前的企业客户就好。
意识到这个模式,使用 iPhone 或者 AppleTV 替换 Mac 也可以实现。因为 AppleTV 不方便插网线,故选择了一台闲置的 iPhone12 搭配 lighting 以太网适配器进行测试。碰到两个问题: lighting 接口理论带宽有 480Mbps,因为在一个接口上下载并转发,实际吞吐还得打 5 折。实际测试下载,最高下载速率只有 10MB/s,实在不够看。 有一个workaround,让iPhone同时接入Wifi,因为有线网卡和无线网卡是不一样的MAC地址,可以分配不同的IP,软路由侧对这两个 IP 负载均衡,那么就可以实现低延迟需求走有线,高带宽需求走无线。 因为经过一层转发,Surge无法识别请求来源设备了,所有来源地址都是软路由。之前使用 SRC-IP 来识别 XBOX 让游戏通通走低延迟的机场,现在没法实现了。

有一台闲置的 mac,打算用来当作家里的网络代理服务器。有几个方案: - (现状)在软路由里面安装 Clash,指定部分设备流量走 Clash,实现透明代理 - 缺点:手机电脑日常使用 Surge,只有路由器使用 Clash,需要额外维护一份 Clash 配置,麻烦 - 使用 Mac Surge 接管 DHCP,让流量走 Surge 过,实现透明代理 - 缺点:稳定性差,一旦 Mac 挂了,整个网络就瘫痪了 - 特定设备主动配置代理服务器为 Mac Surge - 缺点:不是透明代理,可能部分设备无法设置 Proxy - 在方案一的基础上,让 Clash 直接将所用流量通过 socks5 转发到 Mac Surge,Clash 当中只需要配置一条固定的 socks5 策略 目前来看,最后一个方案既能实现透明代理,又不会影响稳定性,还能实现全设备使用 Surge。
https://github.com/valkey-io/valkey/issues/18 看到 Linux 基金会分叉了 Redis 建立了 Valkey,想起前几天另外一个 Redis 分叉 Redict,好奇两个分叉是什么关系,特地去搜了下。 看到这个 issue,Redict 维护者疯狂推销他们的许可证以及 FOSS 协作工具,尝试合并两个开发者社区。而 Valkey 维护者显然更加务实, 不接受更换代码托管和证书。 管窥开源社区的政治生态,挺有意思的。

最近退订了Github两项付费订阅:GitHub Pro($4/m) 和 GitHub Copilot($10/m) GitHub Pro: 一开始订阅诉求是更多的 Codespaces 的单位时间额度,临时开发一些东西可以直接云端编码。 但是用着用着发现机器配置很不灵活,2C8G 和4C16G 的机器只有 32GB 磁盘空间,大一点的仓库下载一下依赖就占满了并禁止磁盘写入了。 如果想要更大的空间,8C32GB 的机器起步开始提供 64GB 的磁盘空间,这样一来 CPU 单位时间配额马上就用完了。 目前使用 Gitpod 了,无法选择 region,网络连接不如 Codespaces,但是配置足够用,实际开发体验可以接受。 GitHub Copilot: 大模型代码补全也发展好几年了,在大多数场景下,各类竞品完全能够提供不输 Copilot 的体验。 促成我寻找替代品的关键是,在远程开发模式下,Copilot 插件总是无法稳定使用 vscode 或者 goland 的 proxy 配置,导致国内的开发机无法正常补全代码。 目前转向使用 Codeium 了,提示速度、质量都非常好,还在代码内行内提供了一些预先配置好的 prompts 用来快速修复错误/重构/注释,功能上更加丰富。
https://blog.jetbrains.com/go/2024/01/18/goland-2024-1-eap-program-and-roadmap/ Goland 2024.1 Beta 更新了,日志上明确提升了性能和 remote dev 稳定性。 今天使用 Gateway 连接了开发机新版的 Goland,整体流畅度相比 2023.3 确实明显提升。之前版本在切换文件或者打开 UI 组件的时候经常会有明显的掉帧,在新版上少了很多类似的情况。 确实可堪一用了,终于不需要使用 VSCode Remote 了。 不过性能开销似乎没啥提升,32c64g 的开发机日常是 20% CPU load + 90% 的内存占用。。。

试着使用 GPT4 把博客的内容国际化了一下,半个月下来,Google 搜索展示量有了明显的上涨。 因为所有内容是富文本,甚至是 markdown 超集,想要翻译并保留格式必然要定义一些 DSL,这个时候就不得不依赖下 GPT4 较强的逻辑推理能力,保证输出的结果可靠性。 不过调试过程中,反复调整 prompt,GPT4 的开销太高了,有点吃不消。还是等后面 GPT4 turbo 放开使用了,考虑自动监控内容变更,自动更新翻译内容。



https://www.recursive.design/ 太喜欢 Recursive 这款可变字体了。 作为 UI 字体,我最喜欢的一点是,固定 font-family(sans/mono)的情况下,调整字重,字体宽度不受影响。在前端开发的时候,如果我们 hover 的时候调整对应元素的 font-weight,往往会出现抖动,需要使用 shadow 来替换 font-weight 来实现相同的效果。如果使用 Recursive 就能很优雅地避免这个问题。 因为支持 monospace 的变种,目前我也使用 Recursive 作为我的代码编辑器的字体,非常好看。

https://blog.cloudflare.com/cloudflare-snippets-alpha/ 有点意思,Cloudflare 的 Snippets,可以套在 API 前面做一些轻量的业务逻辑,有点 API Gateway 的意思。 只不过奇怪为啥不直接叫 middleware 或者 interceptor,更加符合常识。
为了 SEO,用 Telegram API 同步了本频道的内容,展示在我的主页上,后续通过 Google 就能搜索本频道内容了。 https://sorcererxw.com/thoughts

忽然想到,使用类似 Protocol Buffers(protobuf)或者 Thrift 这样的 IDL 声明接口,往往允许修改字段名称,只要保证不修改字段类型和序号,保证数据结构内存结构一致,就不会出现客户端和服务器不一致而冲突的情况。 但如果通过 grpc-gateway 或者 Connect 这样的框架,基于 protobuf,来与前端通过 JSON 而非二进制数据做数据交互,就是另一种情况。在这种情况下,可以随便修改序号,但是绝不能修改字段名称。 如果同时兼容 JSON 和二进制(原生 grpc)两种数据传输,那么就意味着这个 IDL 上的一个字段也不能更改。本质上,这是由于两种模式使用不同的字段索引方式造成的。

【新产品介绍】OpenObserve 是 Rust 开发的一站式 Logs, Metrics, Traces 可观测产品,去年该团队开发了 ElasticSearch 轻量级替代品 zincsearch 迅速获得 15000+ star,并获得 460 万美金种子轮融资,后来转型专注于新的可观测产品 ZincObserve,最近改名为 OpenObserve。 https://openobserve.ai/
还是看看各种 analytics SaaS 吧。除了 Google Analytics,几乎所有类似的服务,价格都不算便宜,Vercel/Cloudflare 之类的都是 20刀一个月,单纯只是网站数据统计的话,感觉意义不是很大,毕竟流量不大,自建 umami 之类的一个月成本也就2刀以内。 对于我来说,更大的痛点其实是服务端的可观测性,自建一套 prometheus/Influxdb + grafana 维护起来蛮麻烦的。所以打算找个原生支持 OpenTelemetry 的 Analytics SaaS,我直接将前端后端数据都通过 OpenTelemetry 打通接入。 最最理想的状态,是能够把 log/metrics/trace/alert 全部依赖一个平台接入。 找了一圈,要不是价格很贵,要不功能不完善,要就不兼容 OpenTelemetry。 想想也是,这类数据统计一旦统计的数据维度多一点,很容易出现统计数据的流量是业务流量好几倍的放大现象。工作中也在维护一个统计服务,也是整个系统的成本怪兽。也能理解为什么各类数据统计 SaaS 这么贵。
最近把自建的 umami 从 1.x 升级到 2.x。根据文档,顺利地升级了 postgres 当中的表结构和数据,但是 2.x 的实例起来之后,一直都无法读取数据库中的数据,看了眼日志,大概是 prisma 处理数据报错了。 无奈,尝试把旧数据清空,原来的报错倒是没了,但是网页上报的数据一直没有正确消费写入。 累了,也懒得回退到 1.x,不太想继续用 umami。
早上尝试在家通过 Surge 作为跳板访问公司内网,发现规则模式下怎么都访问不通。
发现所有请求都直接使用了 Final 的兜底规则,通过机场去访问了公司内网,那肯定是不通的呀,光 DNS 就没法成功(需要使用内网 DNS)。
研究了半天,发现原来是因为自己在内网规则前加了一个 IP-CIDR 规则,整体规则如下的:
IP-CIDR,10.0.0.0/8,PROXY
DOMAIN-SUFFIX,company.org,COMPANY
FINAL,PROXY,dns-failed
根据 Surge 文档所说:在进行规则判定时,Surge 自上往下依次尝试匹配每条规则,如果遇到了一条 IP 类型的规则,那么 Surge 将进行 DNS 解析后再进行匹配。
1. 当处理内网请求的时候,先碰到了 IP-CIDR 规则,当场开始 DNS 查询域名的地址,但是内网 DNS 本地显然访问不通,最后解析失败。
2. 根据 dns-failed 规则使用了 FINAL 的 PROXY 策略,选择了使用机场兜底。
最后把 IP-CIDR 规则移到下方之后,就解决了问题。老实说这个设定确实蛮坑的......
mac(尤其是 intel 的),在唤醒之后常常会碰到 kernal_task 跑满 CPU 的情况,猜测是得把缓存到磁盘的数据读回到内存中,期间会非常卡。 https://discussions.apple.com/thread/5497235
各种办法都试了,效果都不明显。现在找到一个不错的办法,就是开个终端,执行 caffeinate -s,只要我不中止这个进程,系统完全不会休眠,这样就避免了唤醒的问题。

最终返璞归真,在 Github 上开了个仓库存了各种配置文件,clone 到本地手动 ln -s 创建软链接。 这类不是天天都要变动的配置文件,确实没有必要用 icloud 之类云盘实时同步。 分享下重写的 .zshrc,用在我的多个 macos/linux 环境下,使用 Github Action 从我的配置仓库当中自动同步到 Gist,https://gist.github.com/sorcererxw/238f7068c18ba148337f32f9a08d0dbd
昨晚折腾了一晚上的 jetbrains gateway,想着用 goland 远程开发。 整体体验下来就是烂,各种功能和插件需要区分 Host 和 Client,有些插件需要两侧同时安装才能使用,心智负担很高;很多插件本身就是面向客户端模式设计的,在这种前后端分离模式下根本没法使用。 性能的话倒是可以接受,开个 golang 的 monorepo,8c16g 的开发机,索引的时候会打满 CPU,平峰期差不多占用 2c8g。 总的来说,我宁愿使用 neovim 来远程开发,各种体验至少是原生的。

周末倒腾了一下 Surge5 新加入的 Ponte 组网能力。相比一直在使用的 Tailscale 有一个明显的优势,就是不需要自己搭建 DERP 中转服务器了,可以直接使用机场作为中转服务器。
我是用的香港节点作为中转,在公司访问家中mac延迟稳定低于 100ms。因为机场往往是不限速的,使用 VNC 开远程桌面也不需要压缩画质。
通过一些简单的规则就可以实现在外访问家中内网服务:
HOME = select, DIRECT, DEVICE:mymac
IP-CIDR,192.168.50.0/24,HOME
反过来,也可以在家直接通过公司的 mac 作为跳板访问公司内网,非常方便。

之前使用 mackup 把 mac 上的各种配置文件备份到 icloud 了,今天发现 icloud 中的 mackup 目录被错误删除了,在 icloud 上使用文件恢复也找不到……然后 icloud 默默同步文件把本地版本也给删除了,各类配置都是软链接到 icloud 目录的,导致本地所有配置都没了 现在看着唯一一个还开着的加载了之前 .zshrc 的 zsh,再犹豫要不要放弃恢复重新配置一份 .zshrc,积累了几年的配置全都没了😩

connect server 支持 HTTP GET 了,只需要设置幂等级别为无副作用,就会自动为对应 method 配置 GET router。
service ElizaService {
rpc Say(stream SayRequest) returns (SayResponse) {
option idempotency_level = NO_SIDE_EFFECTS;
}
}
idempotency_level 是 protobuf 内置的 method 属性,分为 unknown/idempotent/no_side_effects,后两者都是幂等的意思。
在 RPC 场景中,只要是幂等就代表 Client 端可以安全地重试 RPC 调用,至于是否有副作用指导意义不强。
但是放到 http restful 接口上,GET 往往就等价于无副作用,以此判断是否支持 HTTP GET 还是比较合理且巧妙的。
https://github.com/bufbuild/connect-go/releases/tag/v1.7.0


https://www.bitestring.com/posts/2023-03-19-web-fingerprinting-is-worse-than-I-thought.html TIL,原来清除网站数据或者开匿名模式,并不能避免浏览器指纹标记。

发现自己各种后端服务部署有点混乱,在 Vercel、Railway、Digital Ocean 等 PaaS 上都有部署,对应了不一样的羊毛使用场景。但是发现服务间互相调用会非常麻烦,代码里面需要关心目标服务的具体位置,维护成本和心智负担都不小。
于是写了个“服务发现”机制。使用一个服务发现服务 Discovery Service,通过 Vercel、Railway、Digital Ocean 的 API,不断拉取部署相应平台上部署信息,并存储下来。然后每一个服务会定时从 Discovery 上获取全量的服务列表,然后根据服务的唯一标识映射获取对应的公网地址。这样以来只要保证在 PaaS 上部署服务并暴露公网,客户端就能通过服务名称直接访问。

前几天对信用卡账单的时候,惊讶地发现上个月 MongoDB Atlas 托管数据库扣了将近 200 刀。可能是因为上个月部署了些 cronjob,对数据库用量比较大。但几个小服务产生这么高的消费还是不能接受的。 想着 MongoDB Atlas 是用不起了。但暂时找不到 MongoDB 托管的替代品,试着在 Railway 上起了台 MongoDB 托管实例。把老数据 dump 过去并重启了所有相关服务,完成迁移也就十分钟。 刚看了一眼 Railway 的 Usage 统计,根据每分钟的 CPU/MEM 的平均用量,预估了当月费用,一个月不超过 5 刀 🫠 (比根据读写次数计费划算多了)。 不过如之前所说,Railway 对数据库的可用性没有强的保证,也没有显式的数据备份解决方案。打算先用 Github Action 写个定时 dump 数据库保存到 S3 的脚本,临时先用着。




最近体验 railway.app ,试着部署了些服务,说一些感受: ⁃ 类似 Heroku,服务实例不会被销毁,不会出现冷启动的问题。 ⁃ 计费是按照 CPU 和内存用量+耗时来计算,每个月消费低于 $5 不收费。 ⁃ 不启用付费计划(绑定信用卡)的话,每个月也有 $5 的额度,但是会限制实例每月总在线时长 500 小时(21 天),也就是说想长期部署服务必须启用付费计划。 ⁃ 可以部署数据库 (PG、MySQL、Redis、MongoDB),还支持在前端访问和操作数据库。不过目前没有看到数据库扩容、备份等功能,感觉就是单纯的提供一个数据库容器实例,不适合用于生产。 ⁃ Railway 当中有 Project 的概念,一个 Project 可以有多套环境、部署多个服务/数据库,很像 K8S 的 Namespace,适合用来做业务隔离。 ⁃ 会自动识别项目中的 Dockerfile 构建镜像部署,构建速度也比较快。 ⁃ 和 Vercel 一样,不支持 VPC,也就是说如果做服务间调用,服务只能通过公网域名来互相访问,比较不安全。不过这个功能在 roadmap 中已经是 WIP 状态,可期。 ⁃ 不保留历史日志,需要依赖像 logtail 这类外部日志服务做日志存储。 ⁃ 不支持 cronjob,文档里给的解决方案是起一个实例自己调度…… 总的来说,对于个人开发来说,Railway 体验还可以。但毕竟是一家只有两年的创业公司,平台功能和文档建设还是不够完善。

最新 Next.js13 appdir文档 中, Vercel 引入 Comments 组件,只需要登录 Vercel,就能在页面的任意位置评论。非常像 Figma 的评论系统,只不过把画布换成了网页。 Vercel 也将这个能力开发给了 Vercel 用户,所有 Preview Deployment(非主分支)可以直接开启。默认情况下,只有当前 Deployment 所属组织的成员才能评论,也可以开放权限到任意用户。 一旦发生评论,Vercel 会将评论同步到对应分支的 PR 下面,可以很自然地融入开发流程。 做一个这种模式 Disqus 服务,似乎非常有意思?

https://github.com/topgrade-rs/topgrade 一条命令更新各种包管理中的包,包括 homebrew/zsh插件/pip/npm/docker镜像等等,不更新会死星人感到舒适。
最近需要在数据库存储一批复杂的配置文件,需要原子化更新配置的内部字段的能力。一开始打算用 MySQL,有两个方案: 1. 整个数据结构序列化后塞在一行的一个字段里面。更新的时候在开事务(上行锁)整个读出来更新好写回去。 2. 根据数据结构,老老实实建模,各种 list 表,relation 表,每一个字段都是一列……多数情况下不需要用事务就能单独更新内部字段。 前者省事,但是不优雅;后者足够教条,但太麻烦了。 最后,还是换成了用 MongoDB,整个配置作为 document 写到库里,想怎么原子更新子字段就 怎么更新。虽然 MongoDB 更新文档本质上也是单行事务,但局部更新的语义支持确实比 MySQL 优雅。

https://vercel.com/analytics Vercel 收购了 Splitbee,把访客分析集成到了自家的 Analytics。对于个人项目来说也不需要专门去引入 Google Analytics 了。 一直想试试看 Splitbee,喜欢它的产品调性,现在省事了。
正儿八经地用 Github Codespaces 写了一段时间的代码,把本地开发环境用 Github Dotfiles 配置了一遍。 不得不说体验非常不好,期间无数次压住 clone 代码到本地直接用 IDE 打开的念头。 一方面我非常不习惯使用 VSCode 开发,即便是 VSC 强项前端开发,我也觉得是不如 Goland 智能响应快的。其实也试过通过 Goland 直接 SSH 到 Codespaces 开发,但这就有点脱裤子放屁了。 另一方面是网络不够稳定。虽然大多数时候是稳定的,但一旦碰到连接中断,可能会发现本地变更代码压根没法 commit,刷新一下网页,代码可能直接丢了。开发的时候无时无刻都会焦虑网络问题。 也好,彻底打消了购入 iPad Pro 念头。




https://vercel.com/changelog/improved-monorepo-support-with-increased-projects-per-repository Vercel 把 pro 用户的单 repo 可绑定的 project 数量从 10 提升到 60,可以支持一个中型 monorepo 了

Cloudflare 发布消息队列内测 从Worker开始,Cloudflare为帮助开发者构建大型、可靠的应用程序,不断开发所需基础设施,当遇到不需要立即获得结果,但并发量又需要进行控制时,差不多就需要消息队列上场了 限制 队列个数 10个/每账号 消息大小 ≤128KB 消息重试次数 ≤100次 批量提交消息数 ≤100条 批处理等待时间 ≤30秒 消息吞吐量 ≤100条/每秒 *Cloudflare Queues 与Cloudflare Workers集成,收发消息目前必须使用 Worker,后续将支持其它API接口 *部分限制可能会在后续测试调整、放宽或取消 定价 按每月总操作次数收费;每写入、读取或删除 64 KB 的数据,就计为一次操作,没有带宽流量费用 每月前一百万次操作免费,后续每百万次操作 0.4$ 完整传递一条消息需要 3 次操作:1 次写入、1 次读取和 1 次删除 月账单估算公式为: (消息总数-1000000)*3*/1000000*0.4$ *在内测期间试用免费 >>申请内测 🗂文档 Cloudflare Queues Cloudflare Queues: globally distributed queues without the egress fees #消息队列 Via @Cloudflare_CN

https://medium.com/vanguards-of-code/lodash-is-dead-long-live-radash-d9d52abf428b radash - 取代 lodash 的工具函数库 看起来比 lodash 的代码质量更好更精简。由于使用 TypeScript 编写,相比 lodash 类型校验也更加完善。另外还加了一些基于 async-await 的工具函数。感觉不错。 https://github.com/rayepps/radash
https://hnpredictions.github.io/ 通过爬虫抓取了 hacker news 上所有 prediction 发言。算是某种意义上的“自动挖坟”。得益于 HN 的高质量用户群体,看看几年前用户对科技政治经济的预测,还是蛮有意思的。
https://deephaven.io/blog/2022/08/08/AI-generated-blog-thumbnails/ 有点意思,使用 DALL·E 生成图片作为文章插图。 以前插入一张图是使用关键词去搜索引擎找,然后再给图片配上 alt。 现在是直接给 alt 配上一张图片,还能保证图片独一无二、风格一致,确实是革命性的。

https://www.jetbrains.com/idea/whatsnew/ Jetbrains 全家桶 2022.2 发了,更新了一下 Goland,新功能乏善可陈,本期最大的更新应该是 runtime 从 jre11 切换到 jre17 了,得益于使用了 macOS Metal API,体感上确实流畅了一点。
无意当中看到这个 issue。当我们使用 Notion 作为 CMS 搭建网站的时候,绕不开 Notion 的 S3 图片链接会过期的问题。因为图片会过期,静态生成的网页常常会加载不出图片。哪怕现在去看 Railway blog 依然可以发现有些图片加载不出来。 最简单的避免这个问题方法就是不要将图片 host 在 Notion 上,而是使用外链塞到 Notion 当中,但是比较麻烦,需要先上传图床再做插入。 Issue 帖主选择放弃 SSG,使用 SSR 渲染,可以保证每次下发的图片链接都是最新的,这肯定会导致网页加载慢(不能套 CDN,套了 CDN 就无法保证页面最新了)。 我的主页也是使用 Notion 搭建,但是在服务端做了非常多的预渲染工作,SSR 肯定是无法接受的。我目前的方案是使用 cronjob 拉取网站的 sitemap,使用 Next.js 的 revalidate 功能定期重新生成每一个页面,并保证新渲染出的页面被 Vercel 的 CDN 缓存下来。非常粗暴的方案,但目前来看是能正常工作,前端加载速度也非常快。 不过我还有另外一个未验证的办法:既然我们为了方便,不可避免地直接将图片 host 在 Notion 上。那么我们可以通过 Notion API 定期扫描页面,将 host 在 Notion 上的图片下载下来上传到图床,并替换原图片。虽然看起来在源头上解决了问题,不过似乎也不太省事。

自己的一些服务用需要 redis,直接用了 upstash,一开始以为每天 10k 的 request quota 妥妥够用,没想到放开了用分分钟超额。 最后还是乖乖地在自己的服务器上跑了一个 redis 容器,只作缓存,稳定性低一点,数据丢就丢吧。
一年一度地重构了一遍我基于 Notion 搭建的 个人网站, 从使用 Notion 前端私有接口切换到 Notion 的开放接口, 可以尽量避免接口发生 Breaking Change. Notion 的私有接口经常发生变动导致我需要重新适配, 非常恼人.
另外, Notion 接口当中很多 Block 类型字段不完整或者不满足定制化的前端渲染需要, 比如:
- 部分类型 Block 需要二次查询子节点
- 代码块需要异步渲染高亮
- 多媒体文件需要额外多鉴权
- 需要异步生成 LQIP
- bookmark 类型不包含 opengraph 信息
- 等等……
放弃了在前端直接使用 Notion SDK 提供的数据结构, 而是使用 Protobuf 自定义一套数据结构, 并搭建了一个 BFF 服务来做数据聚合, 把所有需要异步完成的工作全在服务端一次性完成.
这样只需要在 SSG 的时候拉取数据不需要在端上额外计算就能渲染出页面, 无论是对于 SEO 还是性能都能带来提升.
(提前优化爱好者就是我本人了
https://developer.chrome.com/blog/auto-dark-theme/ 原来 Chrome 已经内建了自动夜间模式了, 目测在不久的将来会向普通用户开放。 测试了一下,总体效果不错,相比 Dark Reader 还差一点。 这一改动估计能够让不少设计师和开发者脱离维护 Dark Mode 的苦海,只需要对部分元素定制深色配色,其他全部交给算法就好了。 之后个人项目的前端页面,也不打算花心思为 Dark Mode 定制 Palette 了(面向未来编程😁

使用 Encore 的时候, 使用 Google 登录给了一个提示告诉我当前邮箱有另一个账号在使用, 可以选择合并或者另开账号. 才想起原来一年前我就用 Github 注册过 encore 了呀. 个人认为体验非常好, 每次登录一个服务的时候, 如果这个网站提供了多个第三方登录方式, 如 Google / Github / Twitter 等, 我常常会非常困惑, 忘了之前用的是哪个方式, 担心选错了会创建出一个无用的账号. Encore 的做法避免了这种情况, 但也不阻止你另开账号. 技术上实现猜测并不难: 在用户表上存下用户不同平台的 open id (唯一索引), 以及相应的 email (非唯一索引), 在用户注册的时候都拿用户邮箱去检索比对. 我在个人项目当中去对接第三方登录的时候, 为了精简权限 (第三方登录流程中, 获取用户邮箱往往是需要额外权限的) 和数据库表设计, 往往只会存下 open id, 但在未来扩展其他登录方式的时候, 就失去了账号聚合的可能性了.

https://github.blog/2022-06-14-accelerating-github-theme-creation-with-color-tooling/ Github 出的色彩系统设计工具 Primer Prism, 可以在默认色板上批量调整 HSL 改变整个色系, 有点意思

平时预览 JSON 我一般使用命令行工具 jless (类似 jq, 但能实现折叠)
curl https://example.com/demo.json | jless
常见的场景是从 Chrome DevTool 当中拷贝 curl 出来调用一下并预览, 所以这个时候直接使用 jsonhero 并不方便
所以我写了一个类似 jq 的命令行工具 https://github.com/sorcererxw/jsonhero 来实现将 JSON 输出到 jsonhero 上查看
go install github.com/sorcererxw/jsonhero@latest
curl https://example.com/demo.json | jsonhero

https://buf.build/blog/connect-a-better-grpc Protobuf 管理工具 Buf 团队发布名为 Connect 的 RPC 套件. 他们罗列了一些 gRPC 的问题: ⁃ 过于复杂, 难以调试, 而且庞大的代码库容易出现漏洞 ⁃ 不使用 net/http 标准库 ⁃ 不支持浏览器 而 Connect 是在 gRPC 的基础上, 对其进行优化, 一些特性: ⁃ 精简代码, 包括生成的代码也更加可读 ⁃ 使用 net/http 标准库, 兼容性更好 ⁃ 支持 gRPC/gRPC-Web/Connect 三种协议 ⁃ 只支持 HTTP POST 方法, 同时支持 HTTP/1.1 和 HTTP/2, 同时支持 pb 和 json 两种数据格式 ⁃ 支持完整的 gRPC 协议, 包括 server reflection 和 health checks. 相比 Twitch 家的 twirp, Connect 还是兼容了 gRPC 协议, 而 twirp 更像是一套基于 Protobuf generator 的 JSON-RPC. 看起来 Connect 确实是 “A better gRPC”, 既能兼顾高性能的场景, 也能对受限的环境(浏览器/调试)做 fallback.


Project Volterra 堆叠设计看起很酷, 可以无限扩容算力? 虽然不用 Windows 做开发, 但是看是起来当家用服务器还是不错的选项. https://www.youtube.com/watch?v=yICVNta8jMU

这段时间 Bionic Reading 这个概念又火了一把, 猜测原因是有团队在 HN 上分享了他们制作的一款名为 Jiffy Reader 的 Bionic Reading Chrome Extension. https://news.ycombinator.com/item?id=31475420 最早接触 Bionic Reading 是在 Reeder 上, 个人认为原理大概如此: 按比例将每个单词开头的几个字母加粗加黑, 以让眼睛能够快速地在单词间定位, 提高效率避免走神, 对于英文文章阅读确实效果不错. 不过 Jiffy Reader 似乎尚未发布, 在 Chrome 商店上找到另一款 Bionic Reading 的插件, 体验还是不错的, 可以自定义高亮字母的字重和比例, 推荐. https://chrome.google.com/webstore/detail/bionic-reading-digest-pas/lbmambbnglofgbcaphmokiadbfdicddj/related

太能共情这种在大的技术组织当中放个屁都要写篇文档拉个会议的感受了 https://liou28335.medium.com/many-software-companies-are-a-joke-9f4b10378c7a

刚在 HN 上看到的 https://indigostack.app/ 一键在本地配置开发环境, 包括反向代理配置 SSL/数据库等, 确实能节省不少工作. 界面上将所有组件展示为机架上的一个主机, 也很有意思. 目前测试了一下, 发现软件包非常大有 1.6GB, 猜测是将所有依赖软件都打包进来了. 另外由于还未正式发布, 还是存在 BUG, 不能用于实际生产.

#golang
据我所见,字节的 Go 后端是彻底 polyrepo,一个仓库只会是一个服务,多个服务的公共逻辑会拆成各种包来复用。在我看来是不如 monorepo 来得便利高效的,但也不否认 polyrepo 可以简化权限控制、CI 等各种基建工作。没有绝对的正确选择,这取决不同组织架构。
如果选择 polyrepo,日常开发的时候往往会出现一个需求需要改动多个 repo。如果存在 go mod 依赖,还需要先将依赖 push 到仓库,再在调用方仓库通过 git commit hash 拉新的版本。可以算是比较麻烦的了。
好在 Go 1.18 终于加入了workspace 功能,可以通过 go.work 在本地直接将某一个包指向另一个目录,本地改动代码另一边马上就能调用了,大大降低了跨仓库开发的麻烦。
.
└── gitlab/
├── biz_1/
│ ├── svc_1/
│ │ └── go.mod
│ └── svc_2/
│ └── go.mod
├── biz_2/
│ └── svc_3/
│ └── go.mod
├── common/
│ ├── pkg_1/
│ │ └── go.mod
│ └── pkg_2/
│ └── go.mod
└── go.work
这样一来,只需要用 IDE 打开整个代码根目录并配置好 go.work,立马就能获得与 monorepo 几乎一样的开发体验!




HTML embed 是一个非常有意思的功能,它允许用户将某一个动态内嵌到任意第三方网站上展示。 为了方便访客查看,源网站必须要让 embed 资源支持匿名访问。这简直就是爬虫小子的天堂。只需要通过动态 ID 推断出 embed URL 就能爬到动态内容。 恰恰在海外的互联网生态当中,embed 是一个重要的流量入口,很多网站都会提供这样的功能。 反爬如 Instagram 也能够通过这个方式爬取动态内容。 当然这也不是不可绕过。比如 Linkedin 就对 embed ID 和动态 ID 做了区隔。用户只有在 Linkedin 端内才能通过动态 ID 获取 embed URL,这样就能避免爬虫大规模的爬取数据了。
https://danpetrov.xyz/programming/2021/12/30/telegram-google-translate.html 这一篇文章还挺有意思的,讲的是 Telegram 引入基于 Google Translate 翻译功能,但是使用 私有 API 来薅 Google 羊毛。 这个 API 是用来给 Chrome 浏览器实现文本翻译的,免费提供给用户使用,自然是可以匿名访问的。调用方只需要使用各种方式模拟出一个请求,欺骗 Google 让其认为这是一个来自普通用户的请求。

对 gRPC-web 祛魅了,gRPC-web 所有请求都使用 POST 发送,导致所有读请求都无法被浏览器/CDN 缓存,对于性能来说还是有比较大的影响的。 参考 https://github.com/grpc/grpc/issues/7945 目前看来在 client 端做一层封装,识别请求体并做缓存可以缓解,但毕竟不是 HTTP 协议的原生实现,并不优雅。 但是,基于 IDL 生成 Client 和 Server Stub 实在是太爽了,目前来看还是会继续使用 gRPC web 的。

体验了 arctype,又是一个“协作+X”思路的基础工具。 作为一个本地 SQL Client,素质还是非常不错的,相比 DataGrip 响应速度快,相比Sequel Ace 界面更好看。 另外,arctype 还支持直接连接 PlanetScale 数据库(不需要本地启端口转发),对于 PlanetScale 用户(包括我)非常友好。

苦于 Vercel Serverless 函数上使用 ffmpeg 麻烦: - 无法预装 ffmpeg(配置 lambda layer 感觉很麻烦) - 限制编译产物体积上限,压缩后 (tar.gz) 需要控制在 50MB 以内 Node 当中可以使用 ffmpeg-static,不过对应到 Go 并没有好的方案。 于是最近封装了一个库 github.com/go-ffstatic/ffstatic 。类似 ffmpeg-static 的方案———包含完整的 ffmpeg 可执行文件在库内。不过,我为了使用更简单,直接将 ffmpeg 整个 embed 到 Go 编译产物当中,启动的时候再把它们导出到 tmp 目录中。 不过目前还是有点小问题,ffmpeg 4.x 的 x64 版本的 ffmpeg 和 ffprobe 都有 70+MB,一起封装起来压缩完依然有 50+MB,超过了 Vercel 的限制。 不太可能自己去编译个精简的 ffmpeg 出来,目前考虑使用 ffmpeg 3.x 版本来降低体积。另外,也可以考虑通过编译参数来选择是否打包 ffprobe。

最近把梅林路由器的翻墙代理从 fancyss 切换到了 MerlinClash,不但稳定性提升了非常多,还支持使用 Clash 规则了,强推! https://t.me/merlinclashcat







































